Running an AMD Instinct MI50 on a LattePanda Mu Lite (OCuLink eGPU) for Local LLMs

Written by
Featured Video
Table of Contents
- Hardware & Topology I Used
- OS Install & First Detection
- Install the Ubuntu HWE kernel (recommended, before AMD drivers)
- AMD Driver + ROCm: What Actually Worked
- Install the AMD driver installer 7.0.2, then ROCm
- AMD GPU Driver Doesn't Load at Boot
- Ollama with AMD ROCm
- Building llama.cpp for AMD ROCm (HIP)
- Running a Model with llama.cpp on ROCm
- Token statistics
- Building & Running with Vulkan (No ROCm Needed)
- Install Vulkan runtime + dev bits
- Build llama.cpp with Vulkan
- Run llama-cli with Vulkan
- Token statistics
I’ve been tinkering with a LattePanda Mu Lite and an AMD Instinct MI50 (16 GB HBM2) in an eGPU setup over OCuLink. My end-goals: run Ollama and llama.cpp with GPU acceleration on Ubuntu 24.04 LTS.
This is my living log: everything I did, what worked, and the exact commands I used—warts and all. I’m writing it as a first‑person guide so you can follow (or avoid) my footsteps.
Hardware & Topology I Used
- Host: LattePanda Mu Lite carrier board, Ubuntu 24.04.1 LTS (kernel was
6.14.0-33-genericin my case)

- GPU: AMD Instinct MI50 (gfx906, 16 GB HBM2, passive)

- eGPU + Oculink cable:

eGPU Mount with Oculink Cable:
Connection : Mu Lite PCIe x4 slot → OCuLink host adapter → OCuLink cable → x16 eGPU riser/backplane → MI50
- PCIE 4X to Oculink SFF-8612

PCIE 4X to Oculink SFF-8612:
- Power: 12 V for the carrier (required for the on-board PCIe slot), ATX PSU for the MI50 (2× 8‑pin), lots of airflow through the passive heatsink

OS Install & First Detection
I did a fresh Ubuntu 24.04.1 install to NVMe. After connecting the eGPU chain and powering the GPU first, I booted the Mu and SSH’d in.
Check that the GPU is seen on the bus:
lspci | egrep -i 'amd|ati|vega|instinct'
sudo lspci | egrep 'LnkCap|LnkSta'
# I expect: Speed 8GT/s, Width x4 (PCIe 3.0 x4 over OCuLink)
Install the Ubuntu HWE kernel (recommended, before AMD drivers)
Before installing the AMD GPU drivers/ROCm stack, I install the Ubuntu 24.04 HWE kernel. This keeps me on the supported kernel stream and ensures the extra kernel modules (like KFD) are available for my running kernel.
sudo apt update
sudo apt install -y linux-generic-hwe-24.04
sudo reboot
If /dev/kfd or other modules are missing on the new kernel, I install the modules-extra package that matches the running kernel:
sudo apt install -y "linux-modules-extra-$(uname -r)"
AMD Driver + ROCm: What Actually Worked
My goal was to get ROCm working so apps can use the GPU (/dev/kfd must exist). Here’s the exact path that worked for me.
Install the AMD driver installer 7.0.2, then ROCm
I am installed the AMD installer from the AMD site.
wget https://repo.radeon.com/amdgpu-install/7.0.2/ubuntu/noble/amdgpu-install_7.0.2.70002-1_all.deb
sudo apt install ./amdgpu-install_7.0.2.70002-1_all.deb
# install ROCm user-space + graphics, but NO DKMS
sudo amdgpu-install -y --usecase=rocm --no-dkms
sudo usermod -a -G render,video $USER
sudo reboot now
I then copied the required files as mentioned in this reddit post
1. Download the 6.4 rocblas from here: https://archlinux.org/packages/extra/x86_64/rocblas/
2. Extract it
3. Copy all tensor files that contain gfx906 in rocblas-6.4.3-3-x86_64.pkg/opt/rocm/lib/rocblas/library to /opt/rocm/lib/rocblas/library
4. sudo reboot
AMD GPU Driver Doesn't Load at Boot
If the native kernel driver is not auto-loading, but running sudo modprobe amdgpu on every restart does detect the GPU, then do the following.
-
Find and delete the blacklist file:
grep -r "blacklist amdgpu" /etc/modprobe.d/ sudo rm /etc/modprobe.d/blacklist-amdgpu.conf # Replace with the file found above -
Rebuild the boot config and reboot:
sudo update-initramfs -u -k all && sudo reboot
Ollama with AMD ROCm
I installed Ollama using the command from the ollama site
curl -fsSL https://ollama.com/install.sh | sh
#then started the ollama server
ollama serve
Update: Ollama dropped support for the
gfx906in the0.12.5release. However there is an issue created to add back the support forgfx906
If I run it as a systemd service, I make sure the service user has device access:
# give the 'ollama' user access (if it exists)
getent passwd ollama >/dev/null && sudo usermod -a -G render,video ollama
# ensure the service gets those groups
sudo mkdir -p /etc/systemd/system/ollama.service.d
printf "[Service]
SupplementaryGroups=render video
" | sudo tee /etc/systemd/system/ollama.service.d/rocm.conf
sudo systemctl daemon-reload
sudo systemctl restart ollama
Sanity test (watch the GPU in another shell):
amd-smi monitor --gpu 0
ollama run llama3.1:8b --verbose
Building llama.cpp for AMD ROCm (HIP)
The supported flagset has changed over time. What worked reliably for me:
sudo apt update
sudo apt install -y build-essential cmake ninja-build pkg-config libcurl4-openssl-dev
git clone https://github.com/ggml-org/llama.cpp.git
# from the repo root:
cd ~/llama.cpp
rm -rf build
# Configure for ROCm/HIP; target MI50's gfx906
HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" cmake -S . -B build -G Ninja -DGGML_HIP=ON -DAMDGPU_TARGETS=gfx906 -DCMAKE_BUILD_TYPE=Release -DLLAMA_CURL=ON -DCMAKE_PREFIX_PATH=/opt/rocm
cmake --build build -j"$(nproc)"
How I knew it worked: on startup, llama-cli printed something like:
ggml_cuda_init: found 1 ROCm devices:
Device 0: AMD Instinct MI50/MI60, gfx906:sramecc+:xnack- ...
Running a Model with llama.cpp on ROCm
I used a Qwen3‑14B GGUF from a GGUF repository. I grabbed the new HF CLI and downloaded a Q4_K_M quant (fits in 16 GB):
python3 -m pip install -U "huggingface_hub[cli]"
hf download Qwen/Qwen3-14B-GGUF --include "Qwen3-14B-Q4_K_M.gguf" --local-dir ~/AI/models
Run it:
# make sure compute devices exist (per boot)
sudo modprobe amdgpu && sudo modprobe amdkfd
ls -l /dev/kfd /dev/dri/renderD* # /dev/kfd must exist
# watch the GPU in another shell
amd-smi monitor --gpu 0
# run with "offload as many layers as possible"
./build/bin/llama-cli -m ~/AI/models/Qwen3-14B-Q4_K_M.gguf -ngl 999 -t 4 -c 4096 -b 512
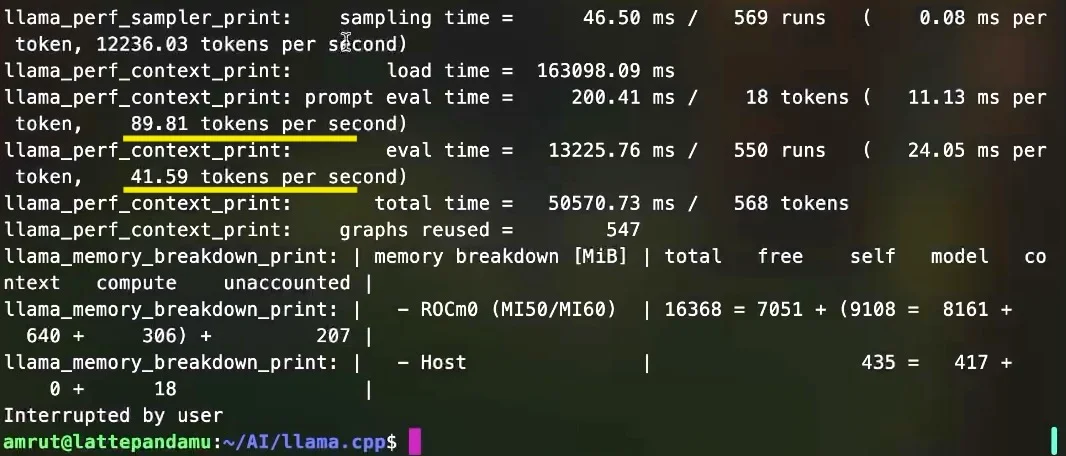
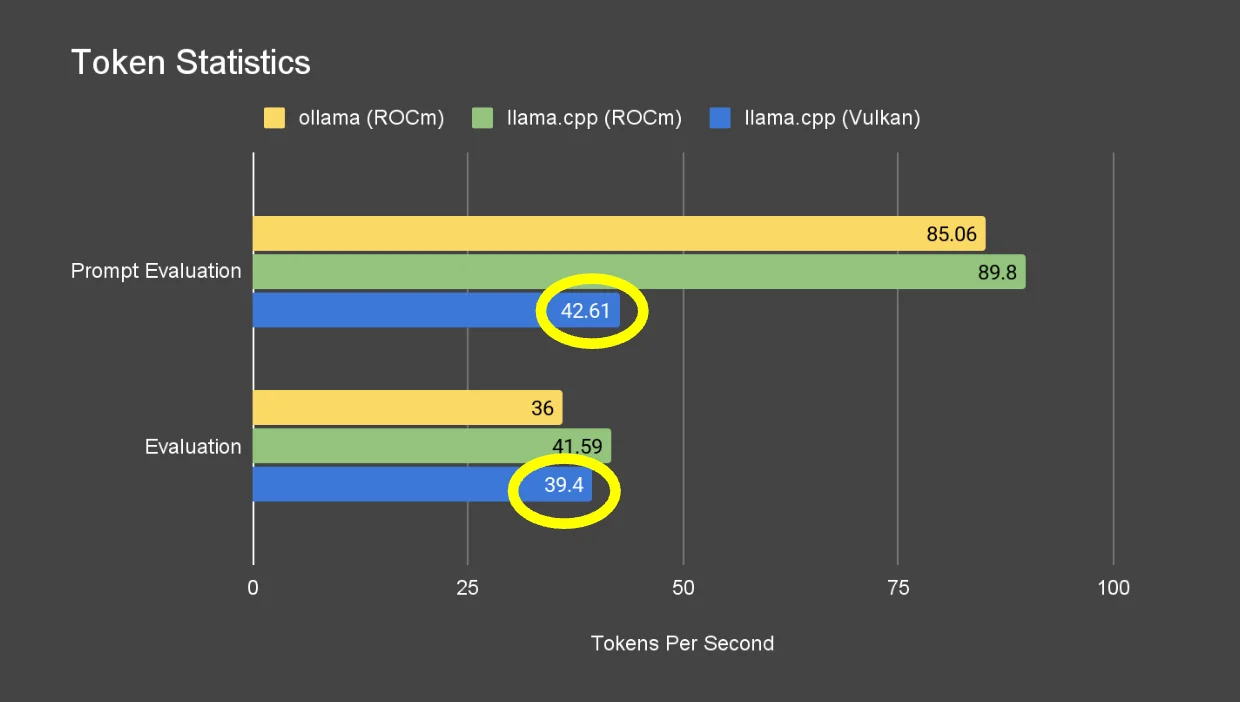
Token statistics

Building & Running with Vulkan (No ROCm Needed)
Vulkan is a handy fallback that skips the ROCm/KFD/Atomics fuss. It’s usually slower than ROCm on AMD, but it works well and only needs access to /dev/dri/renderD*.
Install Vulkan runtime + dev bits
sudo apt update
sudo apt install -y mesa-vulkan-drivers libvulkan1 libvulkan-dev vulkan-tools glslc libshaderc-dev spirv-tools glslang-tools build-essential cmake ninja-build pkg-config
# check the GPU driver is visible to Vulkan
vulkaninfo | egrep -i 'GPU|driverName|apiVersion' | head
Build llama.cpp with Vulkan
cd ~/llama.cpp
rm -rf build
cmake -S . -B build -G Ninja -DGGML_VULKAN=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
On startup you should see:
ggml_vulkan: Found 1 Vulkan devices: ...
Run llama-cli with Vulkan
export GGML_VK_VISIBLE_DEVICES=0 # optional if multiple GPUs
./build/bin/llama-cli -m ~/AI/models/Qwen3-14B-Q4_K_M.gguf -ngl 999 -t 4 -c 4096 -b 512
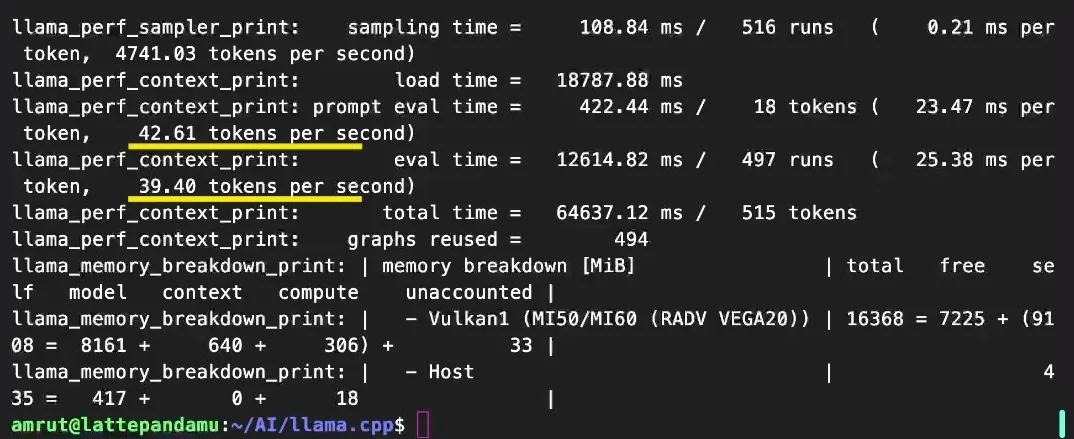
Token statistics